Zheng Zhao
PhD Candidate
I am a final-year PhD candidate in Natural Language Processing at the UKRI Centre for Doctoral Training, University of Edinburgh. I work under the supervision of Shay Cohen and Bonnie Webber and am affiliated with the Institute for Language, Cognition and Computation (ILCC) in the School of Informatics. I am also an active member of The Cohort and EdinburghNLP research groups.
My doctoral research focuses on uncovering and understanding the inner workings of large language models (LLMs). Specifically, I investigate how these complex systems learn, adapt, and represent information across different domains, languages, and tasks.
During my PhD, I have explored topics including:
- Domain learning in language models
- Multilingual representation analysis
- Instruction tuning and multi-task learning
- Contextual understanding and representation learning
These research topics allow me to systematically dissect the computational processes underlying modern language models, providing insights into their learning mechanisms, representational capabilities, and limitations. In addition to my core PhD research, I have worked on topics including discourse analysis, model alignment, personalization, reducing model hallucination, temporal grounding, and summarization.

Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 University of EdinburghPhD in Natural Language ProcessingSep. 2020 - Present
University of EdinburghPhD in Natural Language ProcessingSep. 2020 - Present -
University of EdinburghMasters by Research in Natural Language ProcessingSep. 2019 - Aug. 2020
-
University of EdinburghBEng in Artificial Intelligence and Software EngineeringSep. 2015 - Jul. 2019
Experience
-
 Meta FAIRResearch Scientist InternMay 2025 - Oct. 2025
Meta FAIRResearch Scientist InternMay 2025 - Oct. 2025 -
 Amazon AGIApplied Scientist InternSep. 2024 - Mar. 2025
Amazon AGIApplied Scientist InternSep. 2024 - Mar. 2025 -
Amazon Alexa AIApplied Scientist InternJun. 2023 - Nov. 2023
-
 Goldman SachsSummer AnalystJun. 2018 - Aug. 2018
Goldman SachsSummer AnalystJun. 2018 - Aug. 2018
News
Selected Publications view all
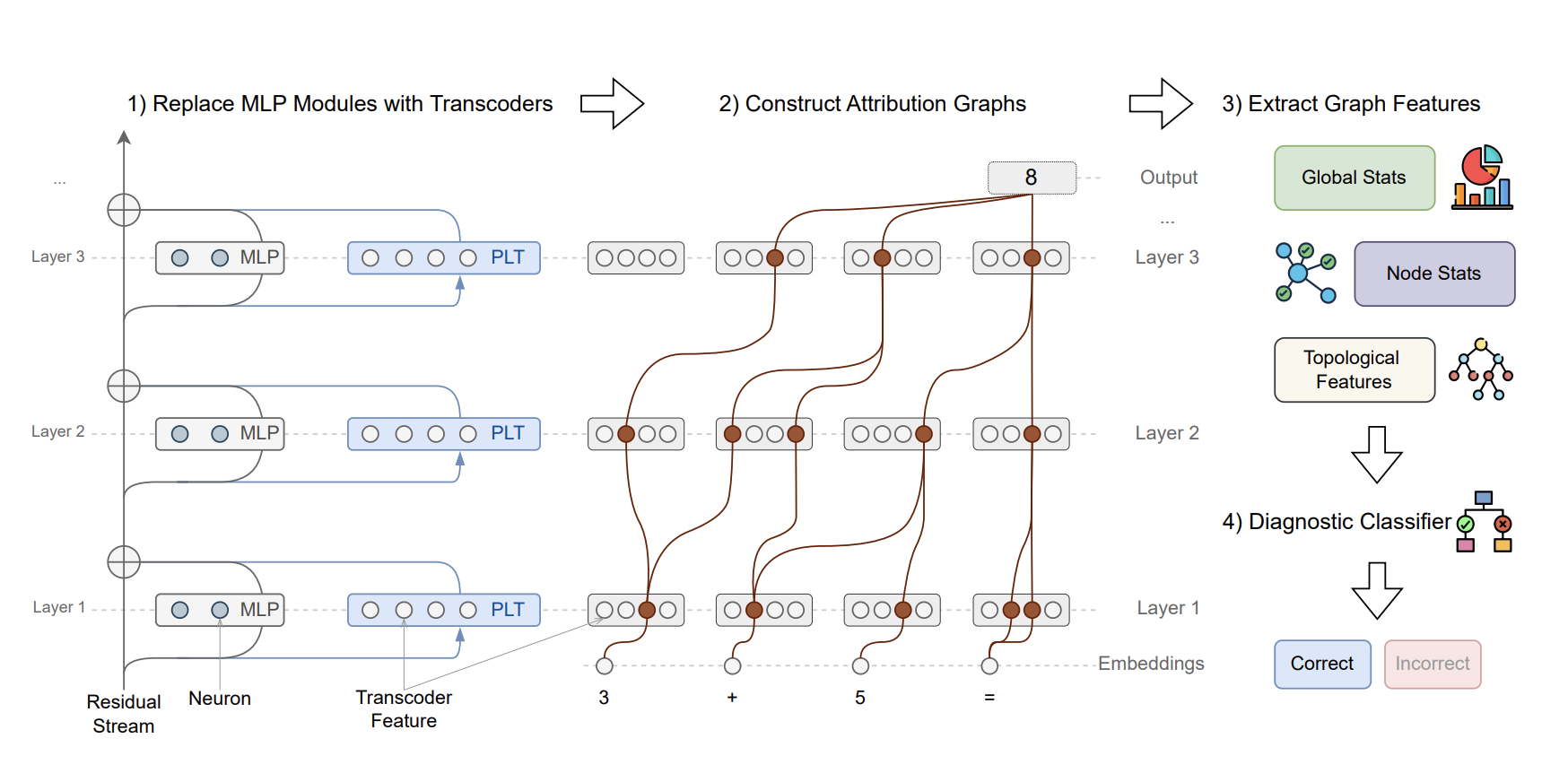
Verifying Chain-of-Thought Reasoning via Its Computational Graph
Zheng Zhao, Yeskendir Koishekenov, Xianjun Yang, Naila Murray, Nicola Cancedda
ICLR 2026 Oral Featured at VentureBeat
This paper proposes Circuit-based Reasoning Verification (CRV), a white-box method that inspects the model’s latent reasoning graph structures to detect errors in chain-of-thought reasoning. It shows that structural signatures differ between correct and incorrect reasoning and that using these signatures enables not just error detection but targeted correction of faulty reasoning.
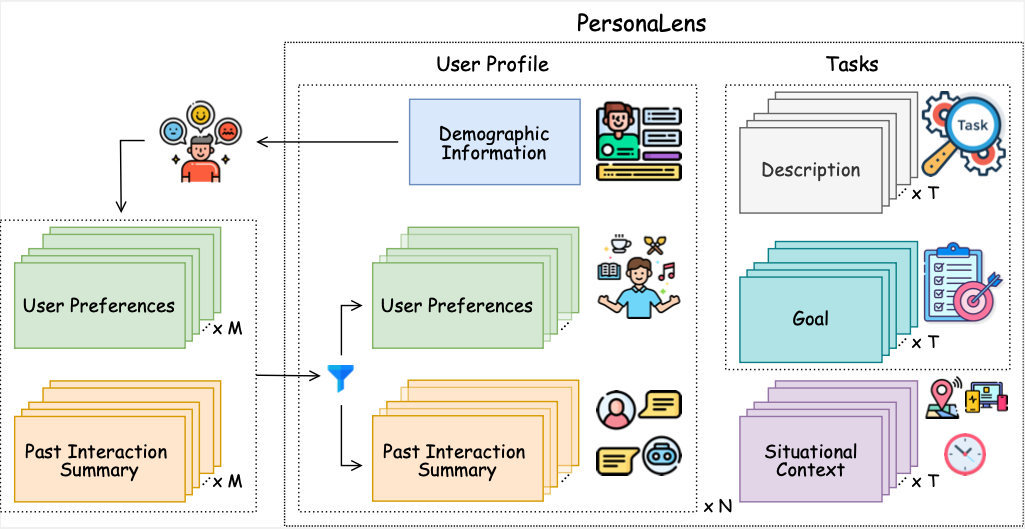
PersonaLens: A Benchmark for Personalization Evaluation in Conversational AI Assistants
Zheng Zhao, Clara Vania, Subhradeep Kayal, Naila Khan, Shay Cohen, Emine Yilmaz
ACL (Findings) 2025
The paper introduces PersonaLens, a benchmark for evaluating personalization in task-oriented AI assistants using rich user profiles and LLM-based agents for realistic dialogue and automated assessment. Experiments show current LLMs struggle with consistent personalization, highlighting areas for improvement in conversational AI.
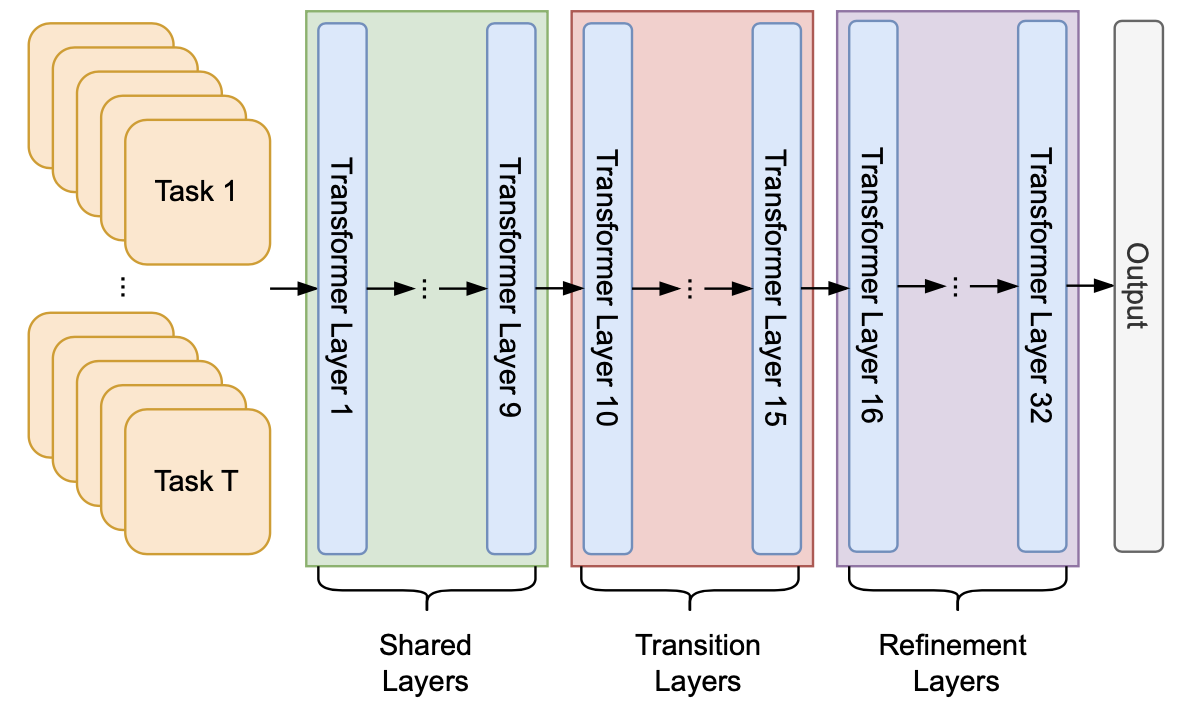
Layer by Layer: Uncovering Where Multi-Task Learning Happens in Instruction-Tuned Large Language Models
Zheng Zhao, Yftah Ziser, Shay Cohen
EMNLP 2024
This paper investigates how instruction-tuned LLMs internally process different tasks, finding that their layers organize into three functional groups: early layers for general features, middle layers for task-specific transitions, and final layers for refinement.
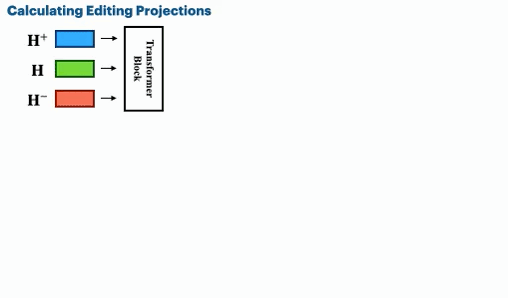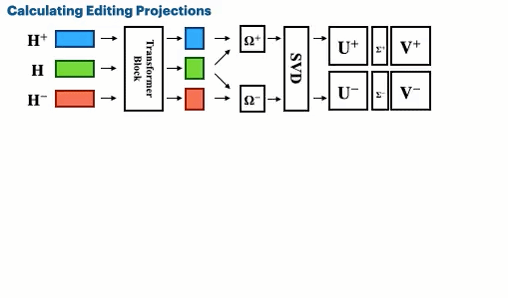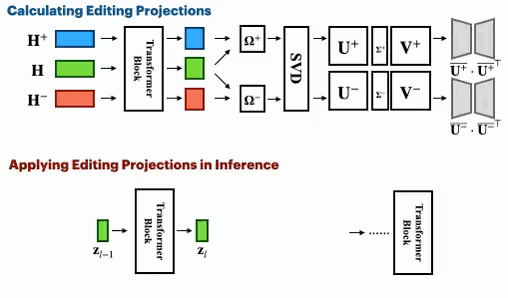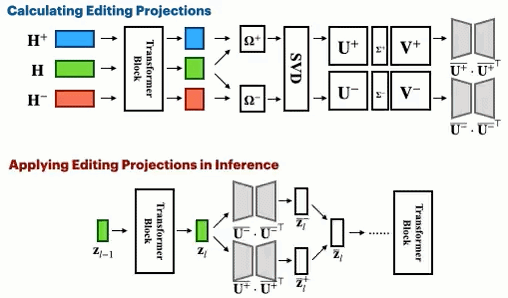
Spectral Editing of Activations for Large Language Model Alignment
Yifu Qiu, Zheng Zhao, Yftah Ziser, Anna Korhonen, Edoardo Ponti, Shay Cohen
NeurIPS 2024
We introduce Spectral Editing of Activations (SEA), a novel inference-time method to adjust large language models' internal representations, improving truthfulness and reducing bias. SEA projects input representations to align with positive examples while minimizing alignment with negatives, showing superior effectiveness, generalization, and efficiency compared to existing methods with minimal impact on other model capabilities.
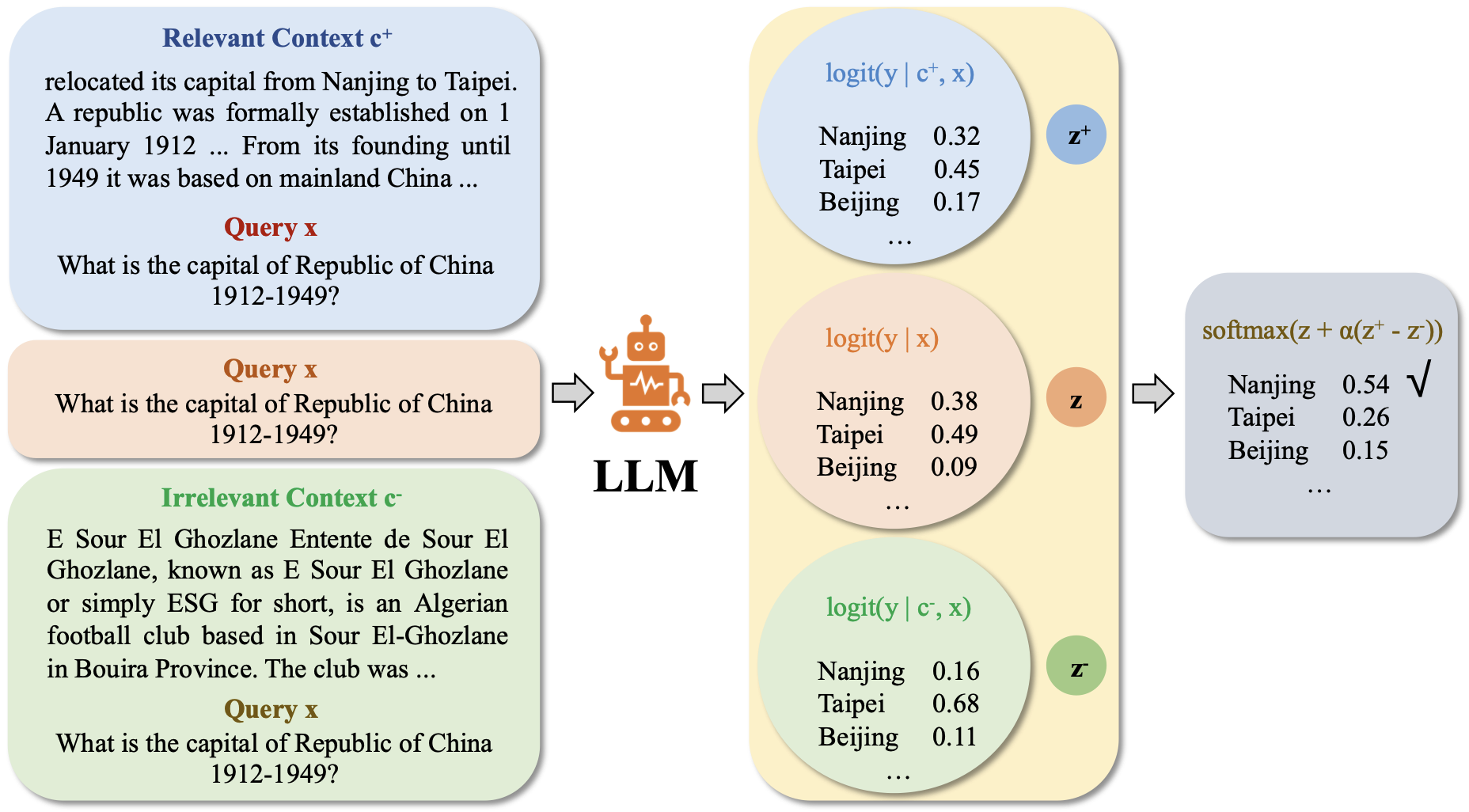
Enhancing Contextual Understanding in Large Language Models through Contrastive Decoding
Zheng Zhao, Emilio Monti, Jens Lehmann, Haytham Assem
NAACL 2024 Oral
This work introduces a novel approach integrating contrastive decoding with adversarial irrelevant passages as negative samples to enhance robust context grounding during generation and operates at inference time without requiring further training.
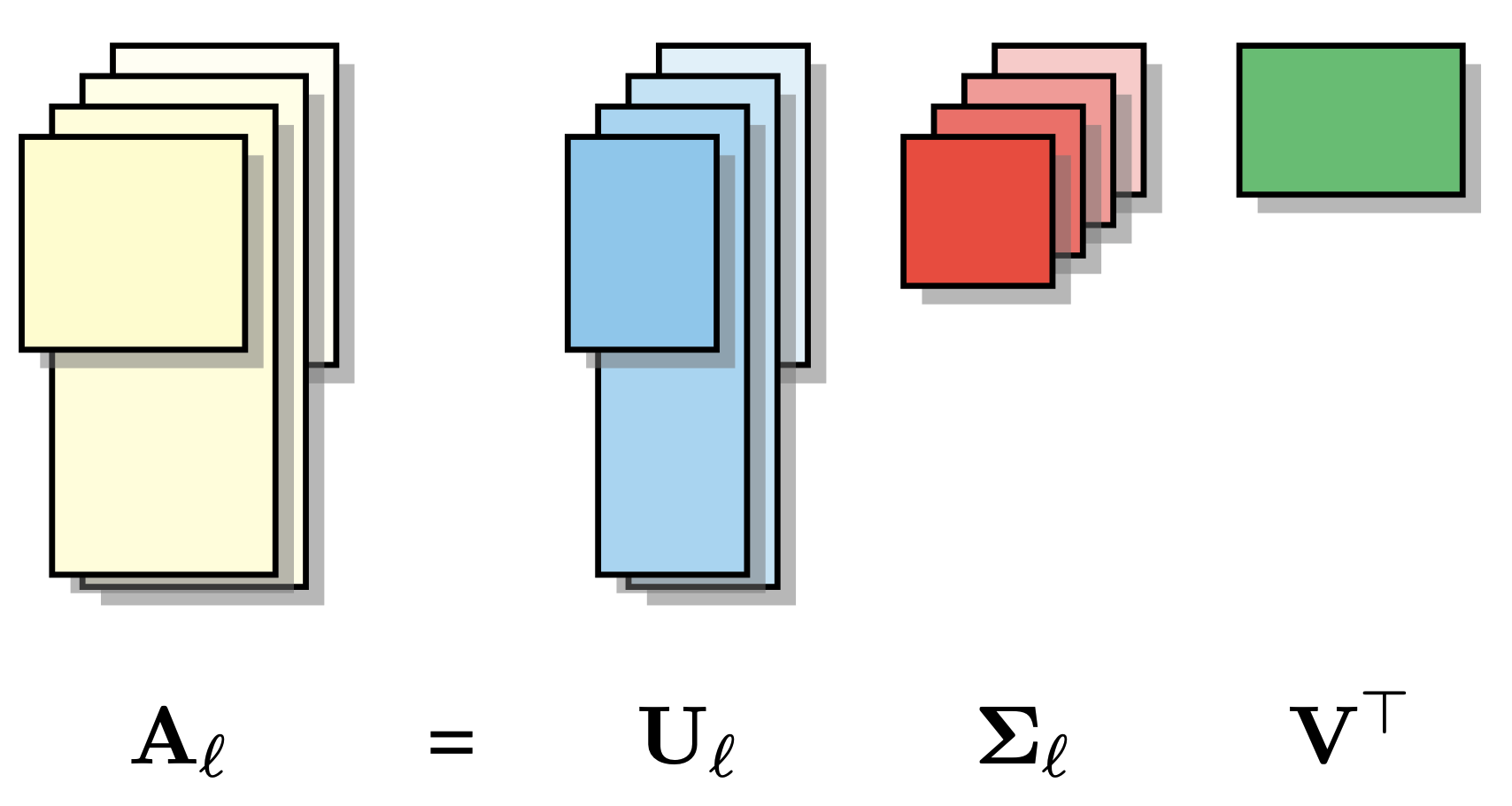
A Joint Matrix Factorization Analysis of Multilingual Representations
Zheng Zhao, Yftah Ziser, Bonnie Webber, Shay Cohen
EMNLP (Findings) 2023
This work presents an analysis tool based on joint matrix factorization for comparing latent representations of multilingual and monolingual models, and finds the factorization outputs exhibit strong associations with performance observed across different cross-lingual tasks.
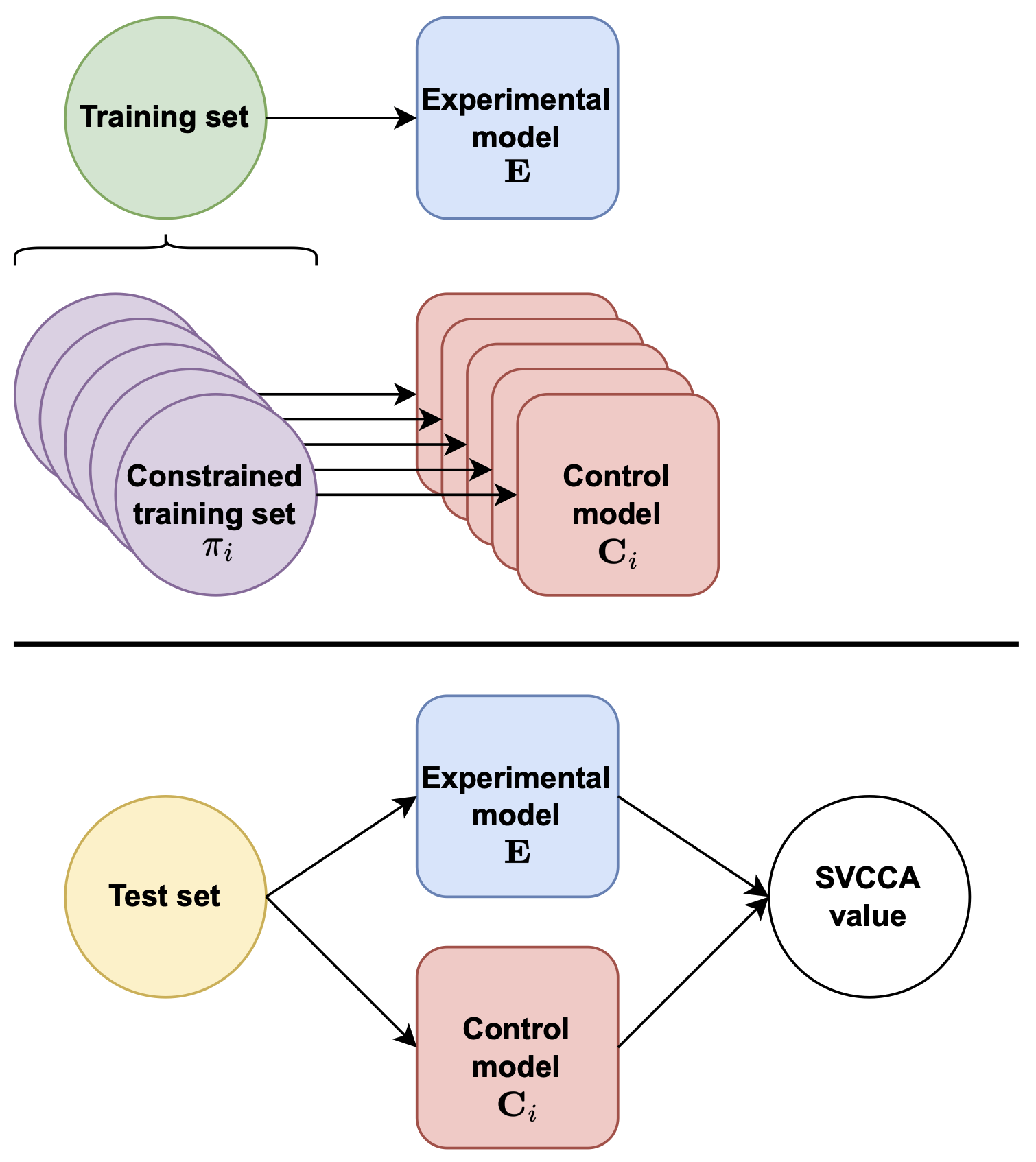
Understanding Domain Learning in Language Models Through Subpopulation Analysis
Zheng Zhao, Yftah Ziser, Shay Cohen
BlackboxNLP 2022
We examine how different domains are represented in neural network architectures, focusing on the relationship between domains, model size, and training data. Using subpopulation analysis with SVCCA on Transformer-based language models, we compare models trained on multiple domains versus a single domain. Our findings show that increasing model capacity differently affects domain information storage in upper and lower layers, with larger models embedding domain-specific information similarly to separate smaller models.
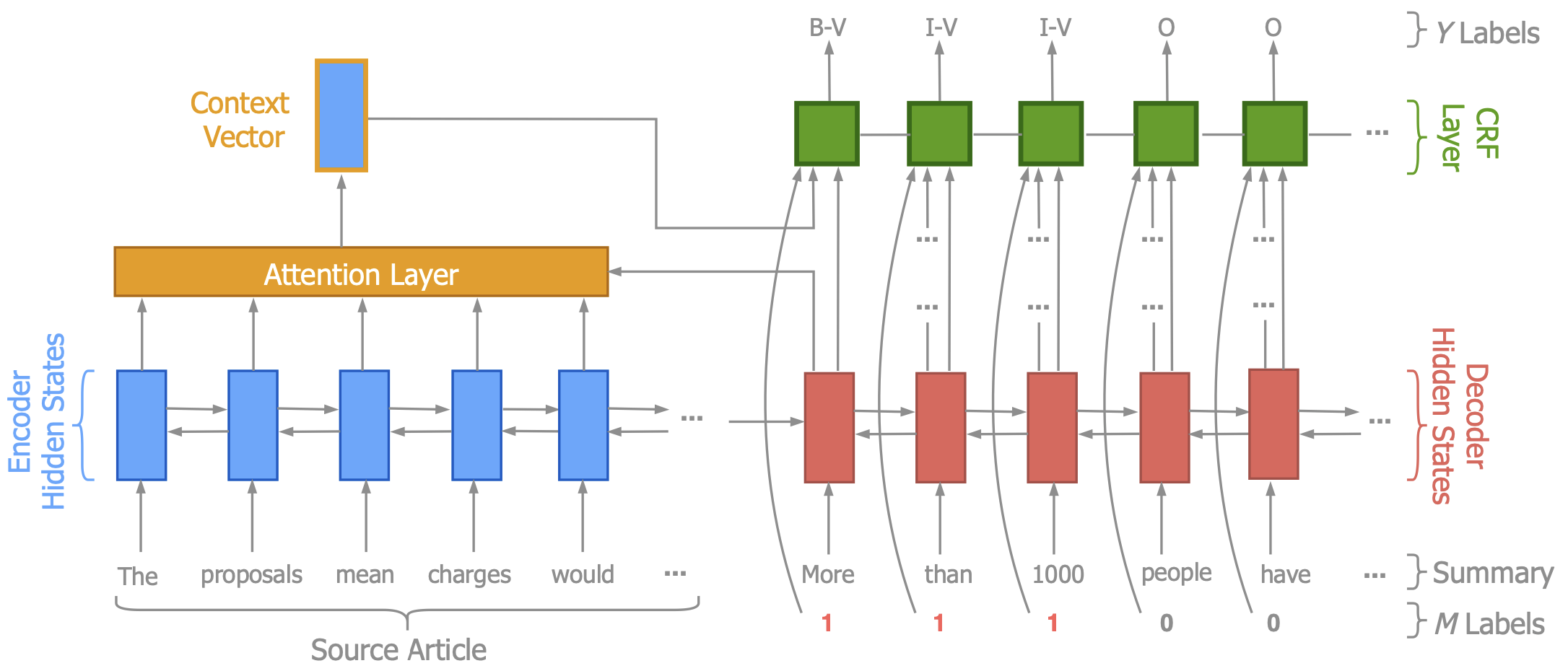
Reducing Quantity Hallucinations in Abstractive Summarization
Zheng Zhao, Shay Cohen, Bonnie Webber
EMNLP (Findings) 2020
Abstractive summaries often hallucinate unsupported content, but our system, Herman, mitigates this by verifying specific entities like dates and numbers, improving summary accuracy and earning higher ROUGE scores and human preference.