2026
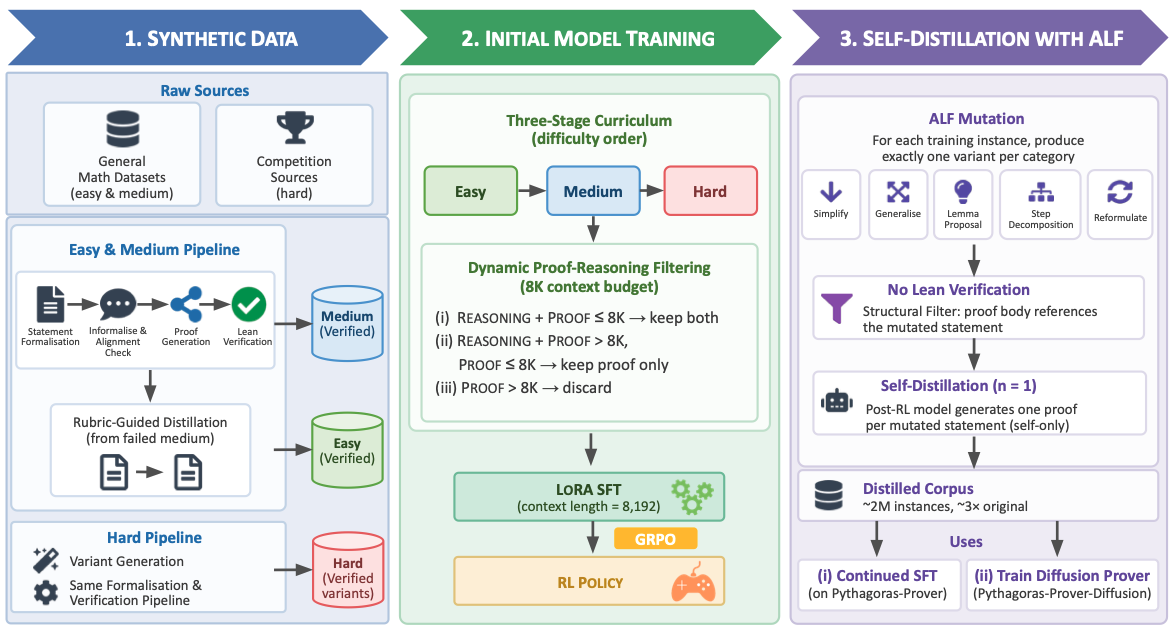
Pythagoras-Prover: Advancing Efficient Formal Proving via Augmented Lean Formalisation
Joshua Ong, Zheng Zhao, Mihaela Stoian, Qiyuan Xu, Haonan Li, Wenda Li, Shay Cohen, Eleonora Giunchiglia
arXiv 2026
This paper introduces Pythagoras-Prover, a compute-efficient family of open-source Lean theorem provers (4B and 32B autoregressive, plus the first diffusion-based prover) trained via Augmented Lean Formalisation (ALF), which expands verified corpora through structured statement mutations without per-instance verification.

Debiasing Without Protected Attributes: Latent Concept Erasure from Textual Profiles
Shun Shao, Zheng Zhao, Anna Korhonen, Yftah Ziser, Shay Cohen
arXiv 2026
This paper introduces H-SAL, a post-hoc method for debiasing language models when protected attributes (gender, race, nationality) are unavailable, using self-description text as an implicit signal. Across encoder and decoder-only models on a new Stack Exchange helpfulness-prediction benchmark, implicit self-description matches or outperforms standard debiasing that requires access to explicit protected labels.
Summarization is Not Dead Yet
Dongqi Liu, Chenxi Whitehouse, Zheng Zhao, Zhuchen Cao, Jian Li, Yabiao Wang
arXiv 2026
This paper revisits the claim that LLMs have solved summarization through a multi-track evaluation across five datasets and five frontier LLMs, finding that human references still lead on informativeness and faithfulness while LLMs only win on surface fluency. Prior "LLMs win" findings are largely attributable to flawed evaluation design.

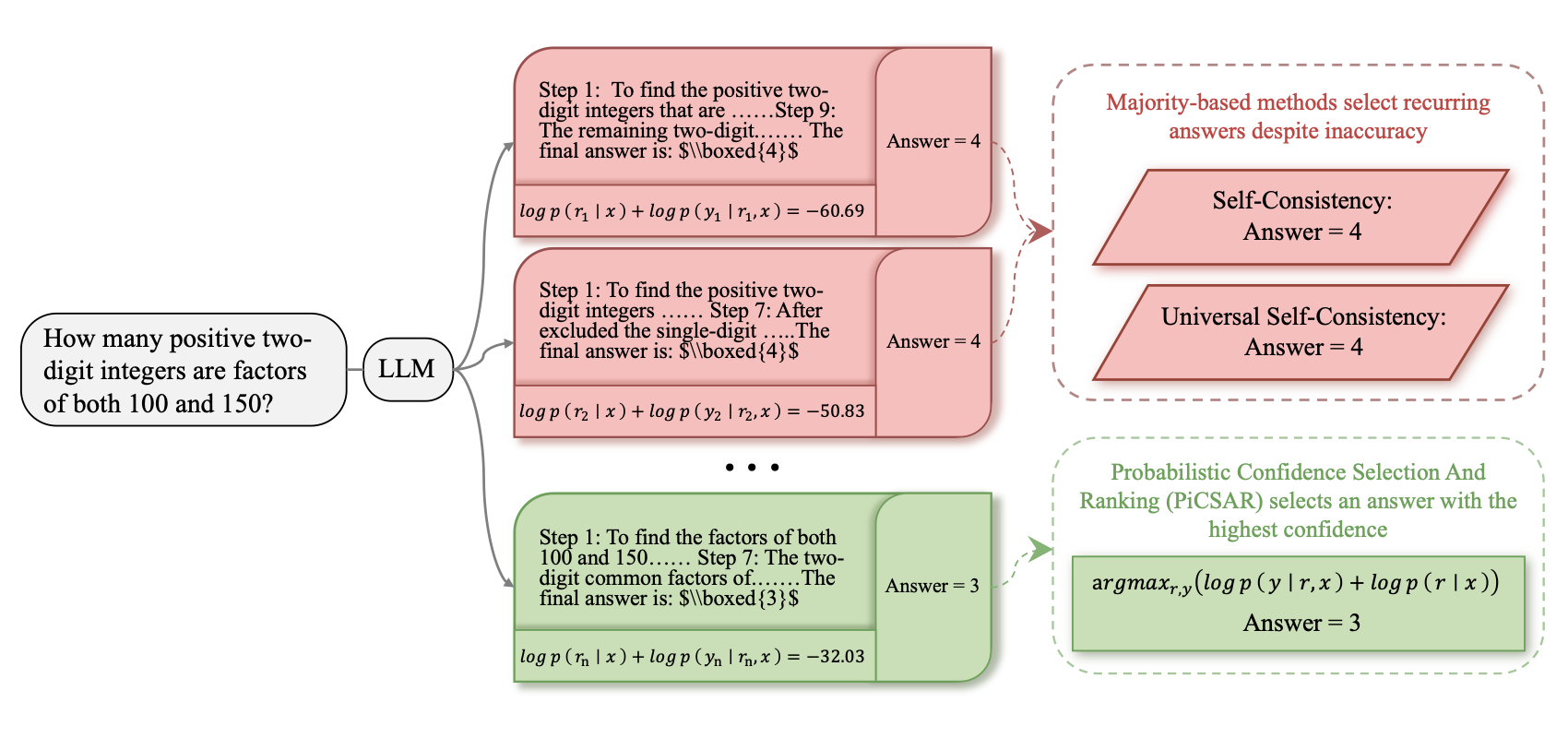
PiCSAR: Probabilistic Confidence Selection And Ranking for Reasoning Chains
Joshua Ong, Zheng Zhao, Aryo Gema, Sohee Yang, Wai-Chung Kwan, Xuanli He, Wenda Li, Pasquale Minervini, Eleonora Giunchiglia, Shay Cohen
ACL (Findings) 2026
This paper presents PiCSAR, a training-free method for selecting reasoning chains in large language models by jointly assessing the plausibility of the reasoning and the model’s confidence in its final answer. Across several benchmarks, PiCSAR outperforms prior selection methods like Self-Consistency while requiring fewer samples.
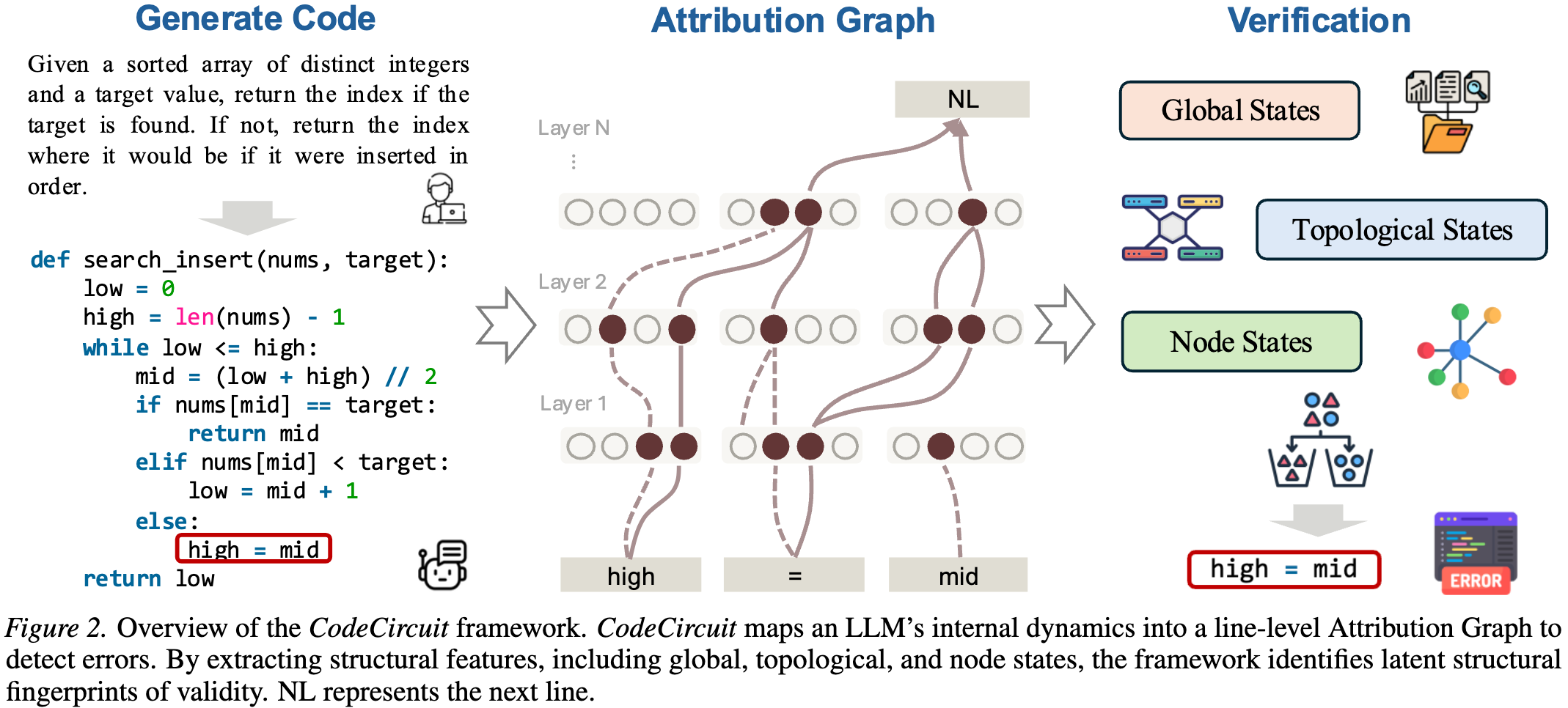
CodeCircuit: Toward Inferring LLM-Generated Code Correctness via Attribution Graphs
Yicheng He*, Zheng Zhao*, Kaiyu Zhou, Bryan Dai, Jie Fu, Yonghui Yang (* equal contribution)
arXiv 2026
This paper conducts an in-depth investigation into a central question: can code generated by LLMs be evaluated for correctness without relying on external assistance? Our key contribution is the demonstration that internal computational structures of LLMs, neural circuits, can serve as indicators of the correctness of generated code.

Self-Improving World Modelling with Latent Actions
Yifu Qiu, Zheng Zhao, Weixian Waylon Li, Yftah Ziser, Anna Korhonen, Shay Cohen, Edoardo Ponti
arXiv 2026
We introduce SWIRL, a framework for self-improving world modelling that learns environment dynamics from state-only sequences by treating actions as latent variables. SWIRL jointly trains forward and inverse dynamics models using mutual information maximisation and an evidence lower bound objective optimized with reinforcement learning. The method improves reasoning and planning performance across multiple benchmarks without requiring action-annotated trajectories.
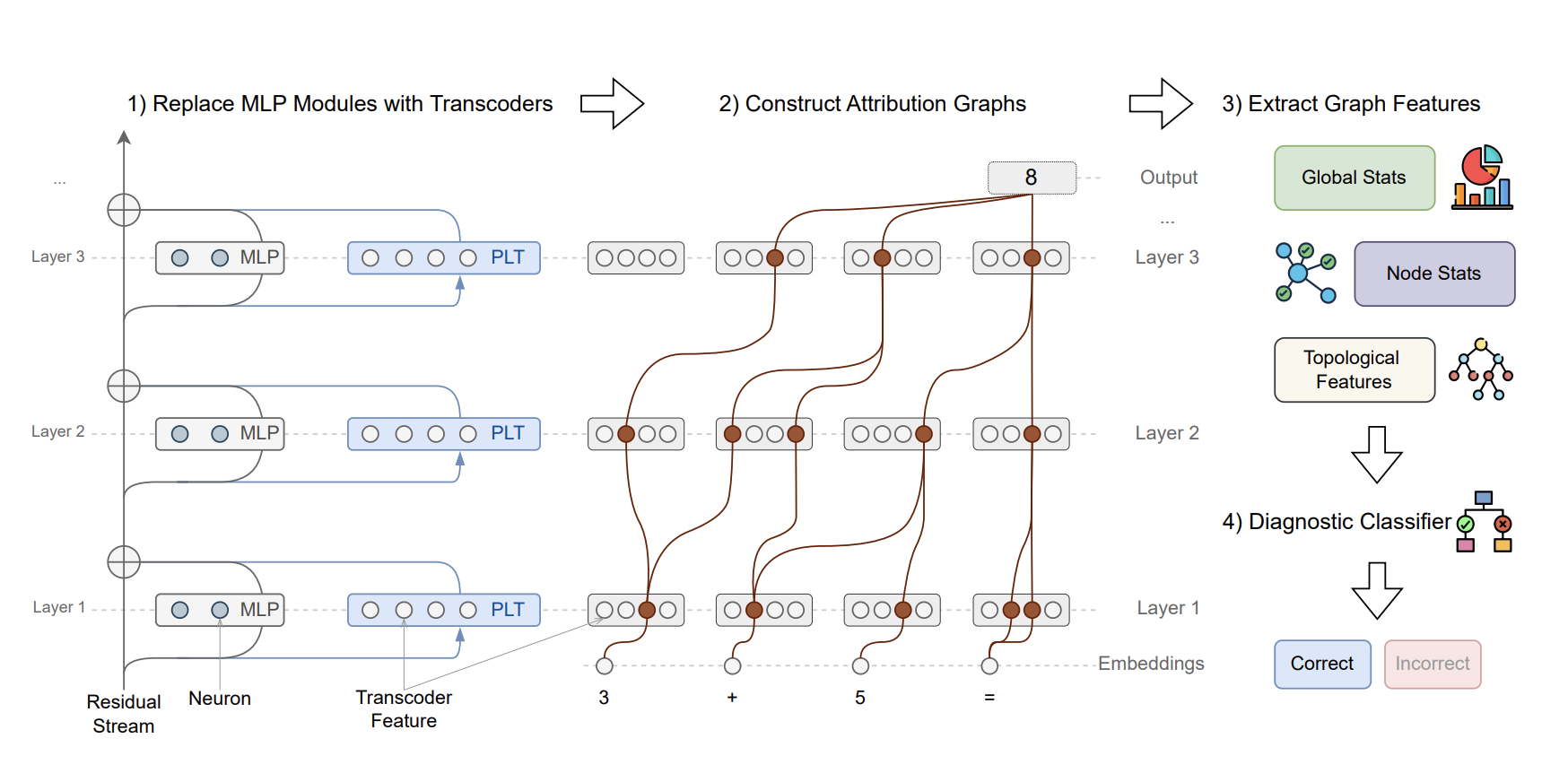
Verifying Chain-of-Thought Reasoning via Its Computational Graph
Zheng Zhao, Yeskendir Koishekenov, Xianjun Yang, Naila Murray, Nicola Cancedda
ICLR 2026 Oral Featured at VentureBeat
This paper proposes Circuit-based Reasoning Verification (CRV), a white-box method that inspects the model’s latent reasoning graph structures to detect errors in chain-of-thought reasoning. It shows that structural signatures differ between correct and incorrect reasoning and that using these signatures enables not just error detection but targeted correction of faulty reasoning.
2025
Iterative Multilingual Spectral Attribute Erasure
Shun Shao, Yftah Ziser, Zheng Zhao, Yifu Qiu, Shay Cohen, Anna Korhonen
EMNLP 2025 Oral
The paper introduces IMSAE, a method for removing demographic attribute information (e.g., gender, age) from multilingual language model representations. IMSAE uses spectral decomposition to iteratively erase attribute-specific components while preserving semantic content, and it works in both supervised and zero-shot settings across multiple languages. The approach effectively reduces demographic leakage without significantly impacting task performance.
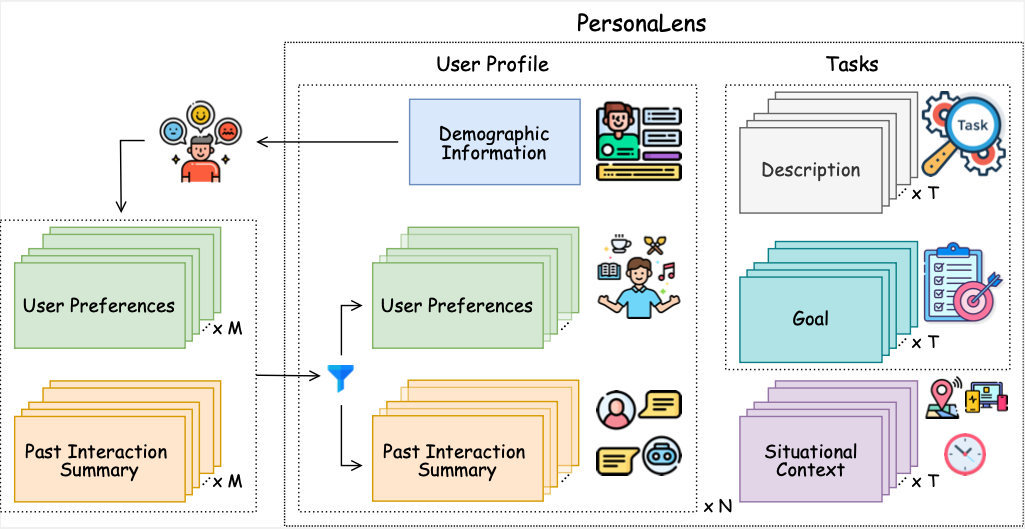
PersonaLens: A Benchmark for Personalization Evaluation in Conversational AI Assistants
Zheng Zhao, Clara Vania, Subhradeep Kayal, Naila Khan, Shay Cohen, Emine Yilmaz
ACL (Findings) 2025
The paper introduces PersonaLens, a benchmark for evaluating personalization in task-oriented AI assistants using rich user profiles and LLM-based agents for realistic dialogue and automated assessment. Experiments show current LLMs struggle with consistent personalization, highlighting areas for improvement in conversational AI.
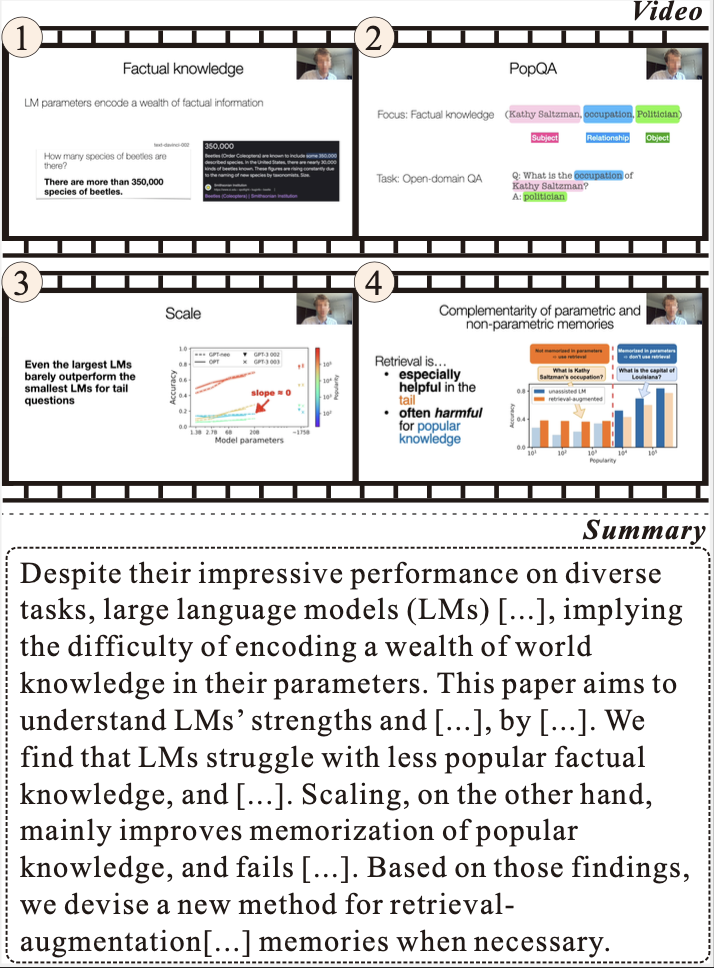
What Is That Talk About? A Video-to-Text Summarization Dataset for Scientific Presentations
Dongqi Liu, Chenxi Whitehouse, Xi Yu, Louis Mahon, Rohit Saxena, Zheng Zhao, Yifu Qiu, Mirella Lapata, Vera Demberg
ACL 2025
This paper introduces VISTA, a dataset of 18,599 video-abstract pairs from top scientific conferences, designed for summarizing scientific presentations. Benchmarking state-of-the-art models, we demonstrate that a plan-based approach improves summary coherence and factual accuracy, though challenges like hallucinations remain.
2024
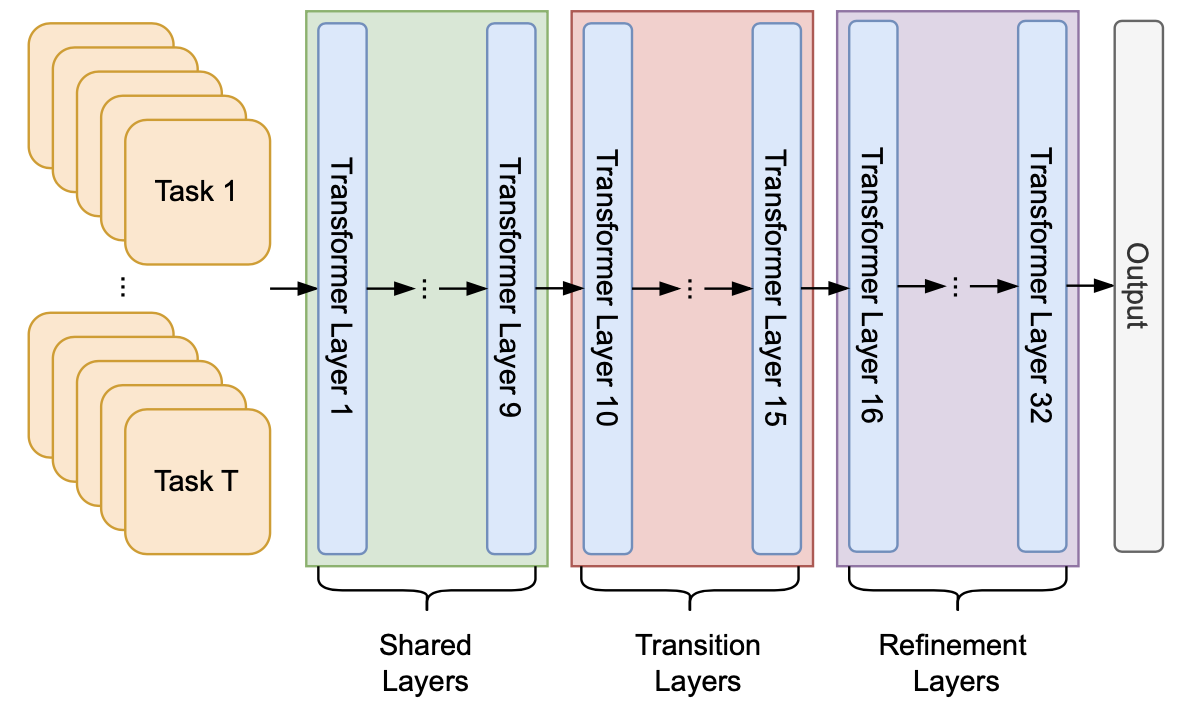
Layer by Layer: Uncovering Where Multi-Task Learning Happens in Instruction-Tuned Large Language Models
Zheng Zhao, Yftah Ziser, Shay Cohen
EMNLP 2024
This paper investigates how instruction-tuned LLMs internally process different tasks, finding that their layers organize into three functional groups: early layers for general features, middle layers for task-specific transitions, and final layers for refinement.
Cher at KSAA-CAD 2024: Compressing Words and Definitions into the Same Space for Arabic Reverse Dictionary
Pinzhen Chen, Zheng Zhao, Shun Shao
Arabic Natural Language Processing Conference (ArabicNLP) 2024
This paper describes Team Cher's submission to the ArabicNLP 2024 KSAA-CAD shared task on reverse dictionary for Arabic uses a multi-task learning framework that combines reverse dictionary, definition generation, and reconstruction tasks. This method, which examines various tokenization strategies and embedding architectures, achieves strong results using only the provided training data.
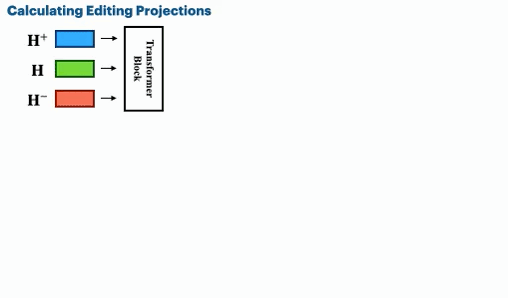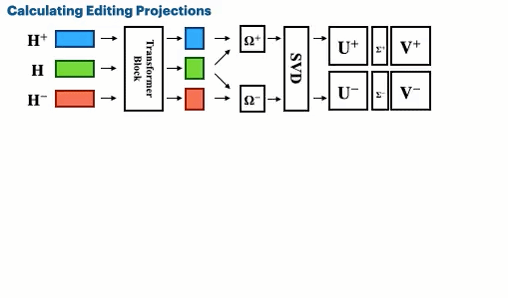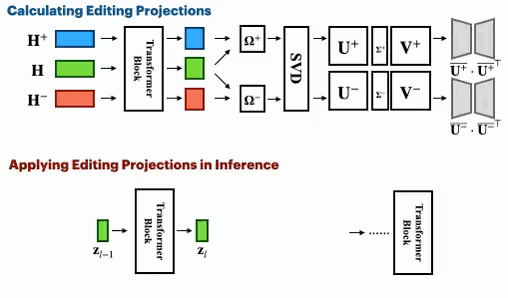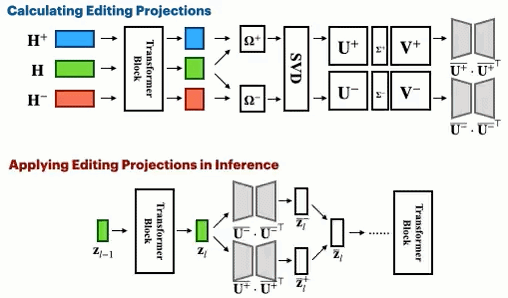
Spectral Editing of Activations for Large Language Model Alignment
Yifu Qiu, Zheng Zhao, Yftah Ziser, Anna Korhonen, Edoardo Ponti, Shay Cohen
NeurIPS 2024
We introduce Spectral Editing of Activations (SEA), a novel inference-time method to adjust large language models' internal representations, improving truthfulness and reducing bias. SEA projects input representations to align with positive examples while minimizing alignment with negatives, showing superior effectiveness, generalization, and efficiency compared to existing methods with minimal impact on other model capabilities.
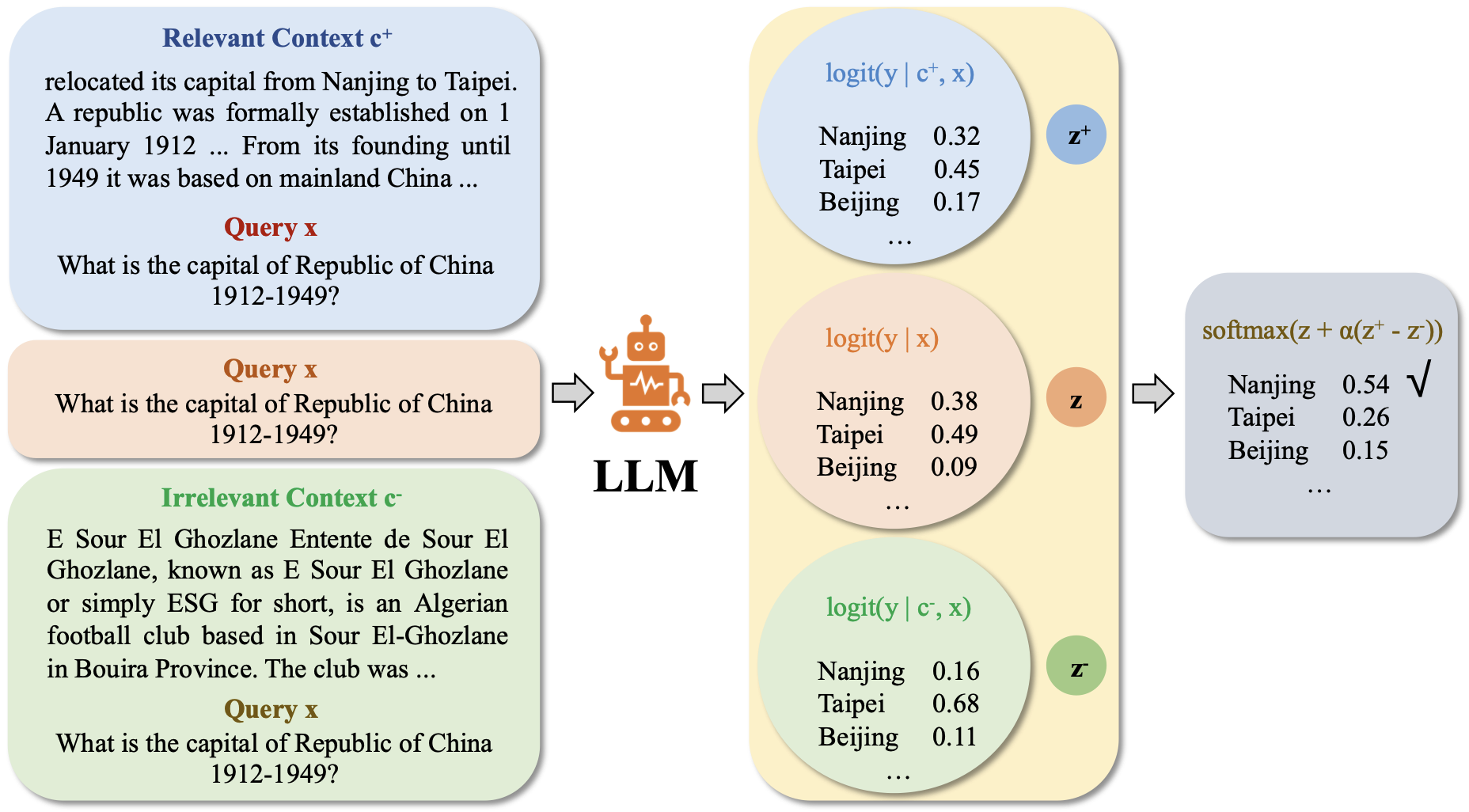
Enhancing Contextual Understanding in Large Language Models through Contrastive Decoding
Zheng Zhao, Emilio Monti, Jens Lehmann, Haytham Assem
NAACL 2024 Oral
This work introduces a novel approach integrating contrastive decoding with adversarial irrelevant passages as negative samples to enhance robust context grounding during generation and operates at inference time without requiring further training.
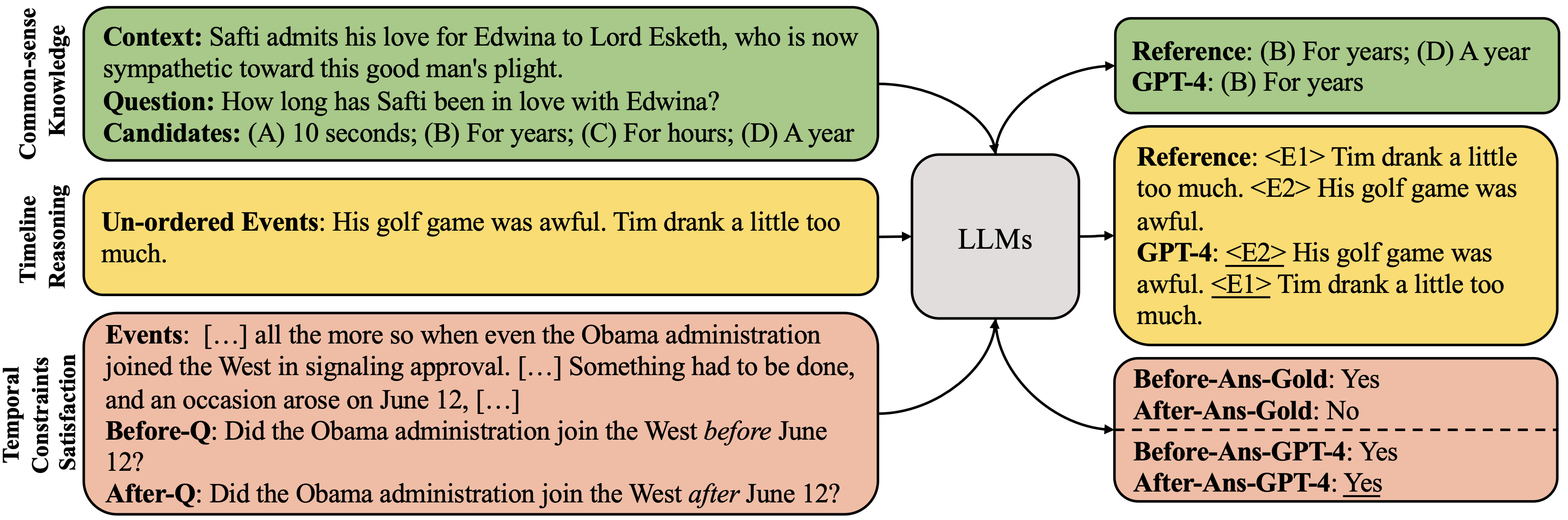
Are Large Language Models Temporally Grounded?
Yifu Qiu, Zheng Zhao, Yftah Ziser, Anna Korhonen, Edoardo Ponti, Shay Cohen
NAACL 2024
We assess whether Large Language Models (LLMs) like LLaMA 2 and GPT-4 have a coherent temporal understanding by evaluating their common-sense knowledge of event structure, ordering, and self-consistency. Our findings reveal that LLMs perform significantly worse than humans and specialized models, struggle with self-consistency, and show limited improvement with larger sizes or advanced techniques. We conclude that current LLMs lack a consistent temporal model, partly due to weak temporal information in their training data.
CivilSum: A Dataset for Abstractive Summarization of Indian Court Decisions
Manuj Malik*, Zheng Zhao*, Marcio Fonseca*, Shrisha Rao, Shay Cohen (* equal contribution)
SIGIR 2024
We present CivilSum, a dataset of 23,350 legal case decisions from Indian courts with human-written abstractive summaries, offering a challenging benchmark for legal summarization. Our analysis highlights that crucial content often appears at the end of documents, underscoring the need for effective long-sequence modeling in summarization.
2023
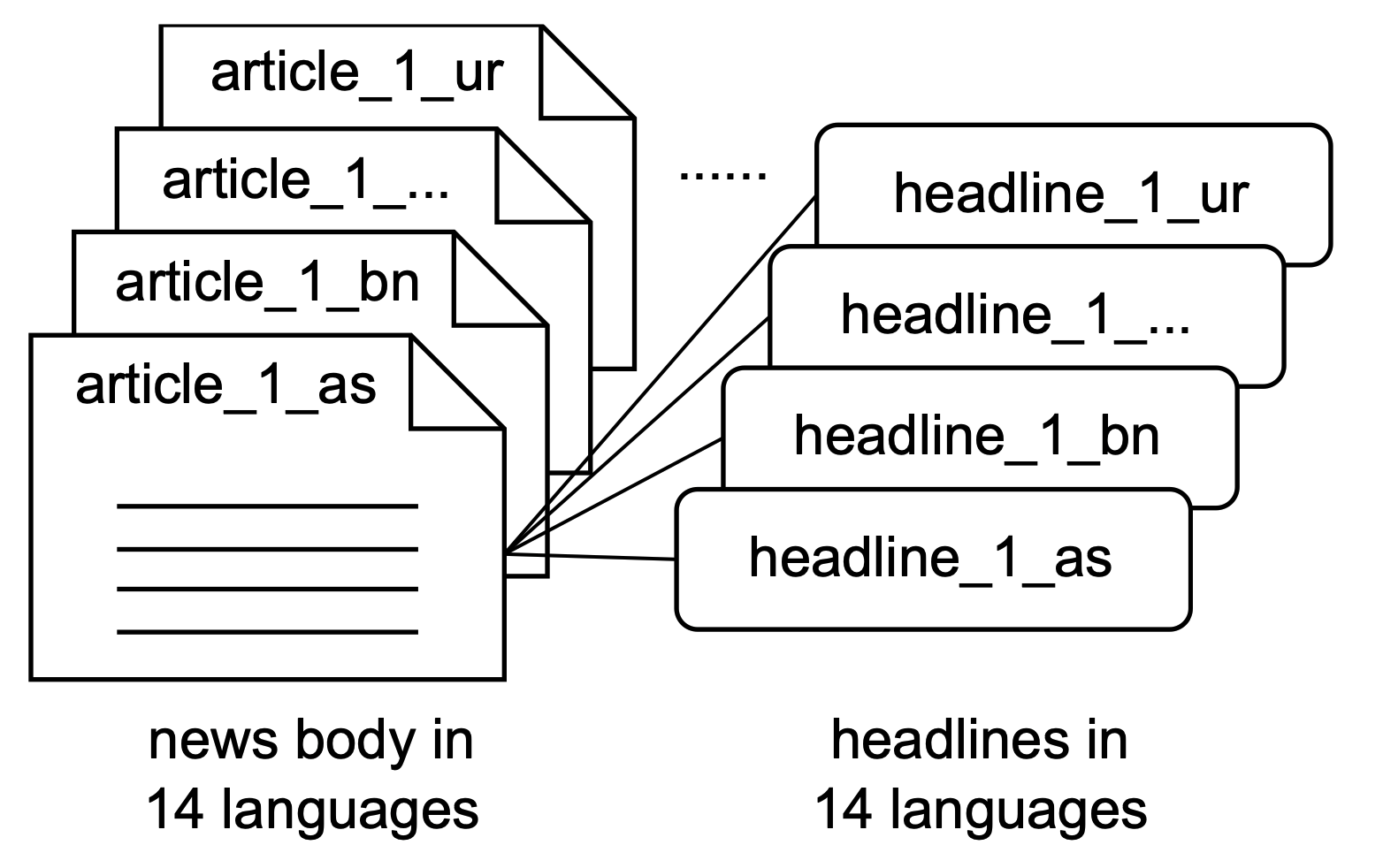
PMIndiaSum: Multilingual and Cross-lingual Headline Summarization for Languages in India
Ashok Urlana*, Pinzhen Chen*, Zheng Zhao, Shay Cohen, Manish Shrivastava, Barry Haddow (* equal contribution)
EMNLP (Findings) 2023
We introduce PMIndiaSum, a massively parallel and multilingual summarization corpus for Indian languages, covering 14 languages and 196 language pairs. We detail our data construction process and provide benchmarks for various summarization methods, demonstrating the dataset's significant impact on Indian language summarization.
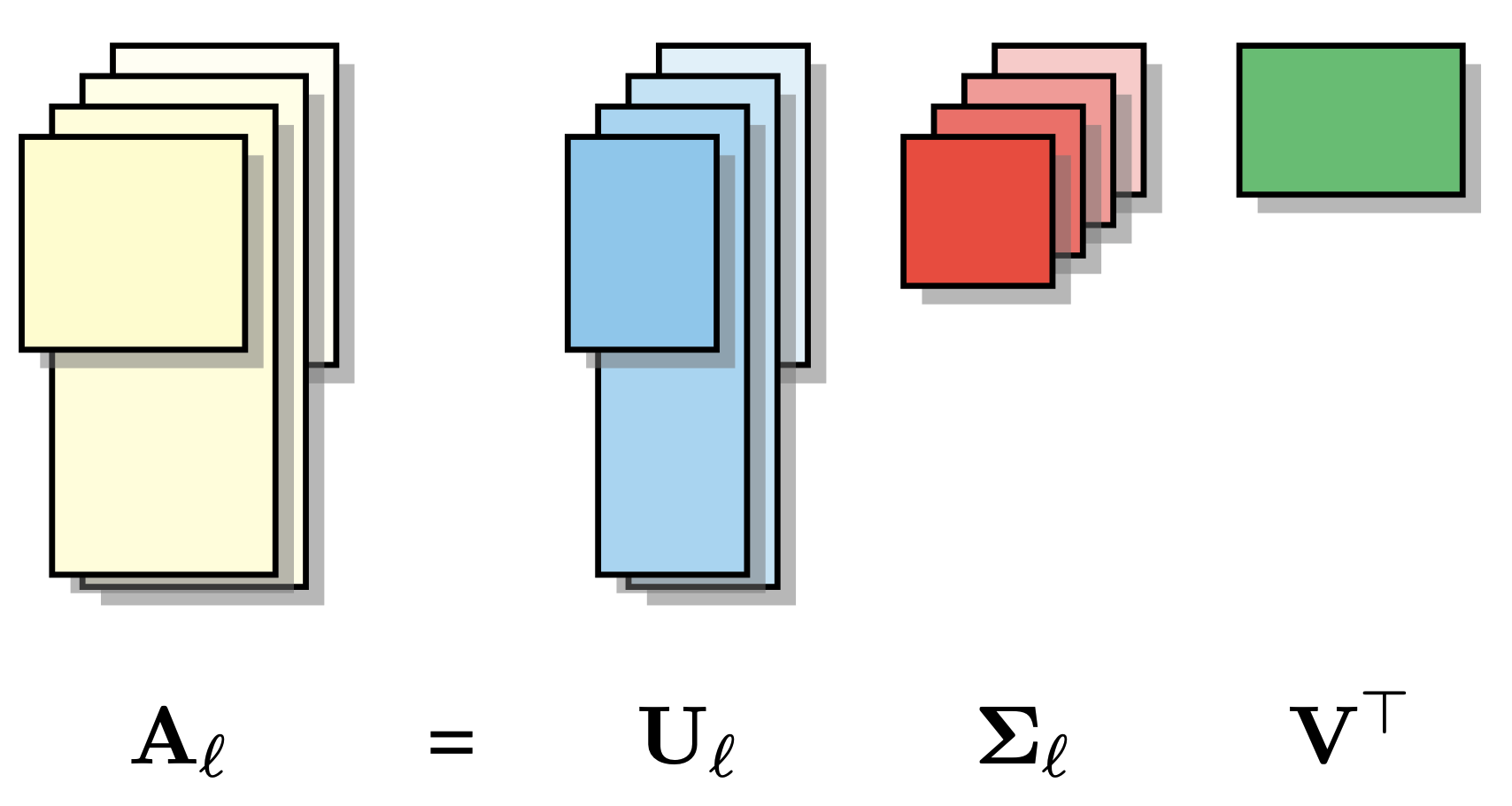
A Joint Matrix Factorization Analysis of Multilingual Representations
Zheng Zhao, Yftah Ziser, Bonnie Webber, Shay Cohen
EMNLP (Findings) 2023
This work presents an analysis tool based on joint matrix factorization for comparing latent representations of multilingual and monolingual models, and finds the factorization outputs exhibit strong associations with performance observed across different cross-lingual tasks.
2022
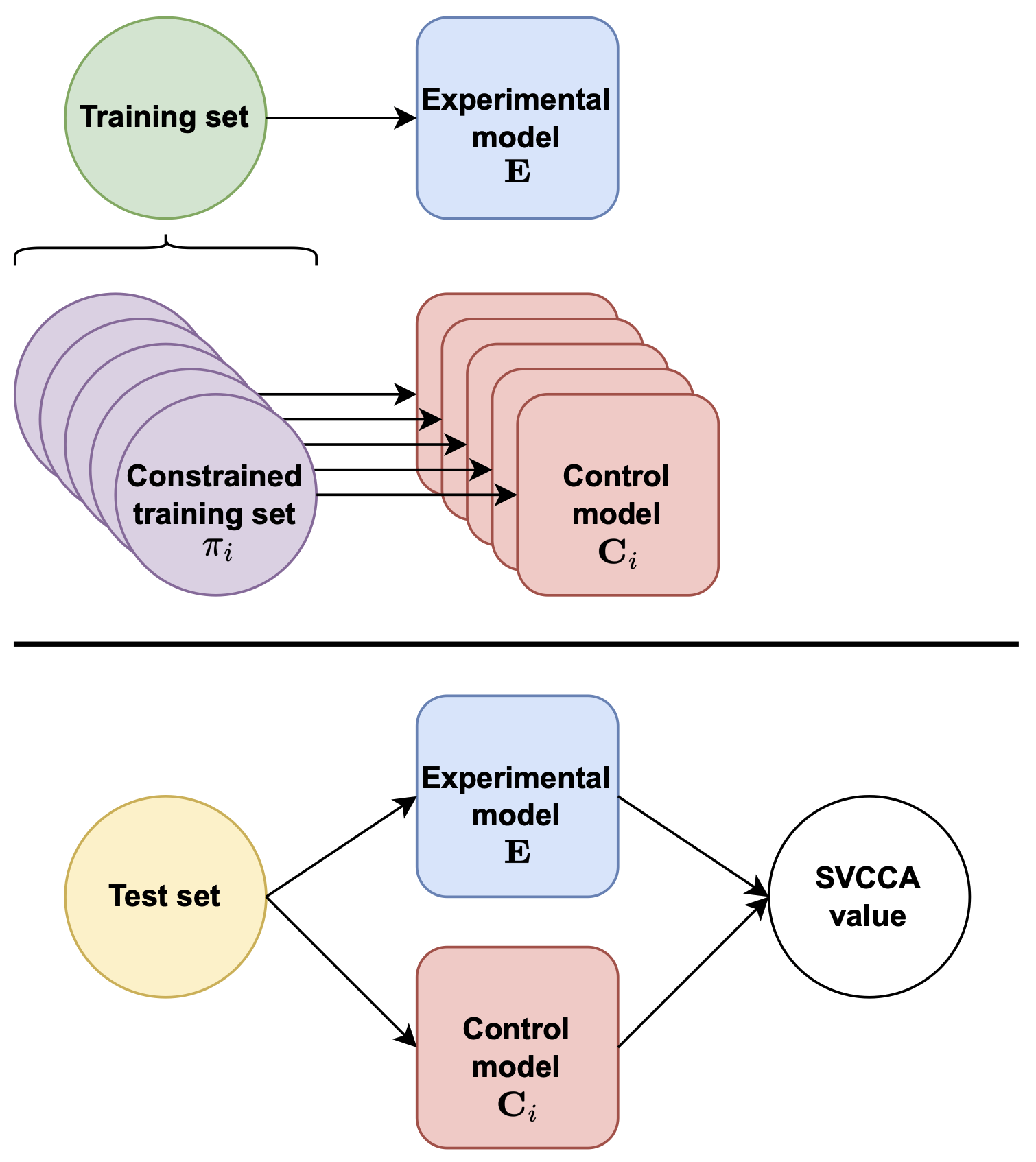
Understanding Domain Learning in Language Models Through Subpopulation Analysis
Zheng Zhao, Yftah Ziser, Shay Cohen
BlackboxNLP 2022
We examine how different domains are represented in neural network architectures, focusing on the relationship between domains, model size, and training data. Using subpopulation analysis with SVCCA on Transformer-based language models, we compare models trained on multiple domains versus a single domain. Our findings show that increasing model capacity differently affects domain information storage in upper and lower layers, with larger models embedding domain-specific information similarly to separate smaller models.
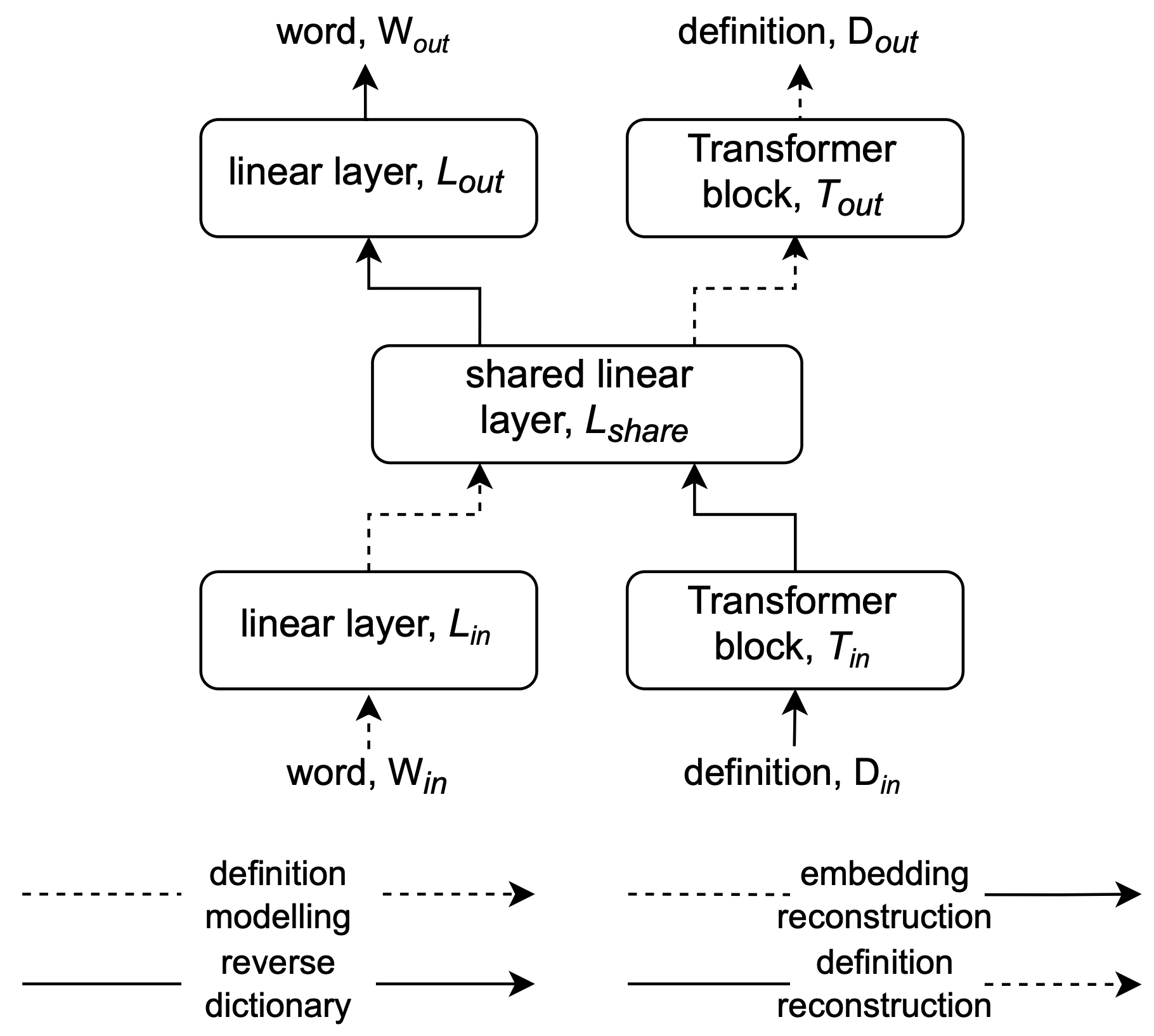
A Unified Model for Reverse Dictionary and Definition Modelling
AACL-IJCNLP 2022
We developed a dual-way neural dictionary that retrieves words from definitions and generates definitions for words, learning both tasks simultaneously using shared embeddings. Our model performs well on benchmarks and is preferred by human evaluators, demonstrating its practical effectiveness and the benefits of multiple learning objectives.
To Adapt or to Fine-tune: A Case Study on Abstractive Summarization
Zheng Zhao#, Pinzhen Chen (# corresponding author)
Chinese National Conference on Computational Linguistics (CCL) 2022
In this work, multifaceted investigations on fine-tuning and adapters for summarization tasks with varying complexity: language, domain, and task transfer provide insights on multilinguality, model convergence, and robustness, hoping to shed light on the pragmatic choice of fine-tuning or adapters in abstractive summarization.
Edinburgh at SemEval-2022 Task 1: Jointly Fishing for Word Embeddings and Definitions
International Workshop on Semantic Evaluation (SemEval) 2022 Honourable Mention for Best System Paper
This paper describes a winning entry for the SemEval 2022 Task 1 on reverse dictionary and definition modeling, using a unified model with multi-task training. The system performs consistently across languages, excelling with sgns embeddings, but reveals that definition generation quality remains challenging and BLEU scores may be misleading.
2021
Revisiting Shallow Discourse Parsing in the PDTB-3: Handling Intra-sentential Implicits
Workshop on Computational Approaches to Discourse (CODI) 2021
In PDTB-3, thousands of new implicit discourse relations were annotated within sentences, complicating the task of identifying their locations and senses compared to inter-sentential implicits. This paper analyzes model performance in this context, highlighting results, limitations, and future research directions.
2020
Extending Implicit Discourse Relation Recognition to the PDTB-3
Li Liang, Zheng Zhao, Bonnie Webber
Workshop on Computational Approaches to Discourse (CODI) 2020
This work presents data to support the claim that the PDTB-3 contains many more implicit discourse relations, and methods that can serve as a non-trivial baseline for future state-of-the-art recognizers for implicit discourse relations.
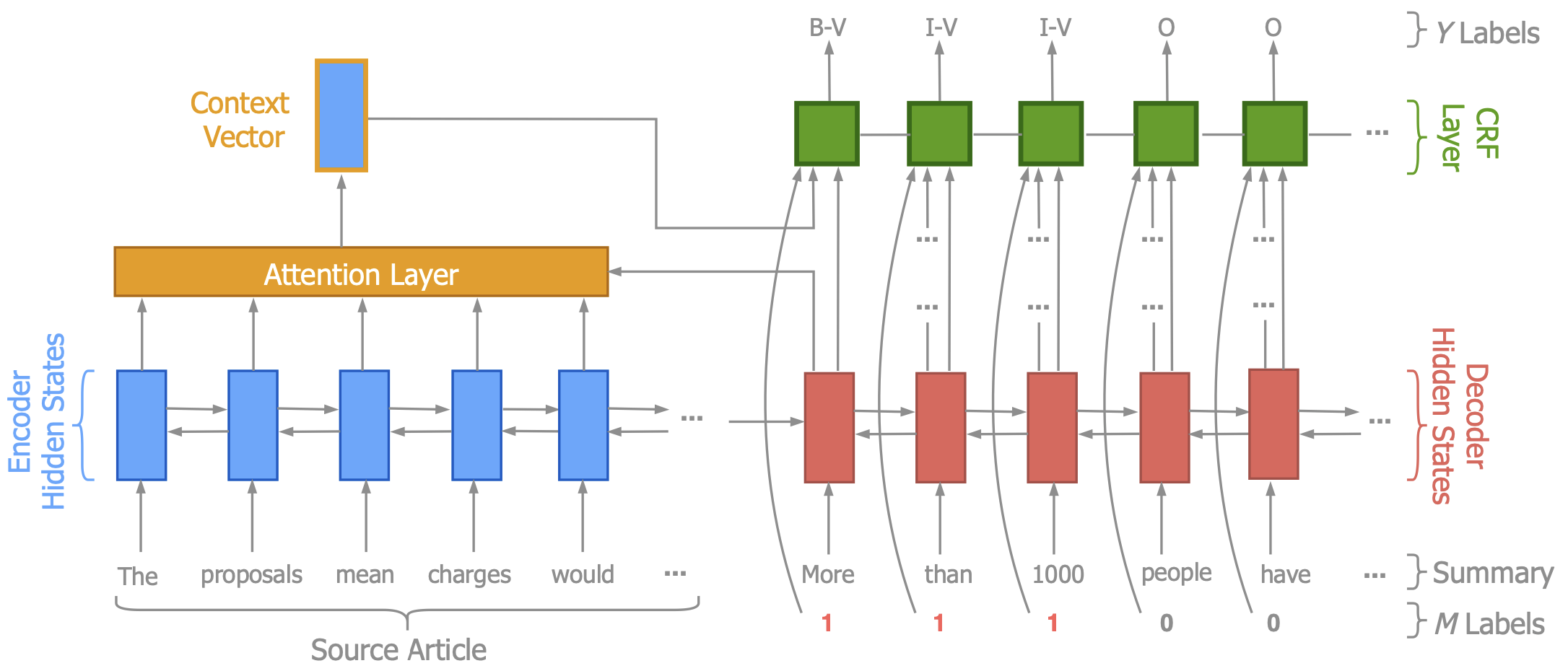
Reducing Quantity Hallucinations in Abstractive Summarization
Zheng Zhao, Shay Cohen, Bonnie Webber
EMNLP (Findings) 2020
Abstractive summaries often hallucinate unsupported content, but our system, Herman, mitigates this by verifying specific entities like dates and numbers, improving summary accuracy and earning higher ROUGE scores and human preference.